HDFS、YARN、MapReduce
大数据基础 概述 4V Volume 海量的数据规模;Variety 多样的数据类型;Velocity 快速的数据流转;Value 发现数据加载。
大数据在技术架构上带来的挑战 对现有数据库管理技术的挑战(TB以上结构化的存储);经典数据库技术没有考虑数据的多类别;实时性的技术挑战;网络架构、数据中心、运维的挑战。
大数据带来的额外挑战:数据隐私。
Google大数据技术 存储容量 GFS;读写速度 BigTable;计算效率 MapReduce
Hadoop 开源的分布式存储+分布式计算平台,可以对多机器的海量数据进行分布式处理的框架。其拥有成熟的生态圈,可存储在廉价的机器上。
Hadoop 主要包括四部分:
Hadoop Common:Hadoop 共用包;
Hadoop Distributed File System(HDFS):可提供高吞吐量的分布式文件系统;
Hadoop YARN:工作调度 & 资源管理;
Hadoop MapReduce:基于 YARN 可并行处理大数据集的框架
狭义的Hadoop即为这三者的总和,而广义的Hadoop是指Hadoop生态系统,生态系统中的每一个子系统只解决某一个特定问题域,是多个小而精的系统。
HDFS 特点:扩展性 & 容错性 & 海量数据存储
将文件切分成指定大小(可配置,默认128M)的数据块并以多副本的形式存储在多个机器上。
数据切分、多副本、容错等操作对用户是透明的。
YARN Yet Another Resource Negotiator,负责整个集群资源的管理和调度(作业占用CPU及内存)。
特点:扩展性 & 容错性(Task异常进行一定次数的重试)& 多框架资源统一调度(跑Spark等额外类型的作业,14年Spark逐渐代替MapReduce称为Hadoop缺省执行引擎。)
MapReduce Hadoop MapReduce 是 Google MapReduce 的克隆版
特点:扩展性 & 容错性 & 海量数据离线处理
HDFS 如果要自行设计一个简易的分布式文件系统,可能会将大小不同的文件以多副本的方式存在在多台机器上,并且记录文件存在哪台机器上等元数据。这样的缺点是:不管文件多大都直接放在一个节点上会造成网络瓶颈且很难进行并行数据处理;存储负载较难均衡,部分节点的利用率较低。
而HDFS的做法是将每个文件先进行拆分,每块大小可设置(如128M ),每个Block多副本的方式进行存储。大小一致的Block会让机器的存储负载好很多,且便于并行处理。
HDFS架构 1个Master(NameNode/NN) & N个Slaves(DataNode/DN)
实际生产部署时, 一个机器部署NameNode,其他每个机器部署一个DataNode。
Replication Factor:副本系数(副本因子)。每个文件可以单独配置副本因子和 Block Size。
HDFS的文件只能写一次(除非 appends truncates),且在任意时间内只能有一个 writer 进行写操作,不支持多并发写。
Hadoop伪分布式安装
JDK安装并添加至环境变量
安装ssh,并配置免密登录
1 2 3 sudo yum install ssh ssh-keygen -t rsa cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys
下载并解压 hadoop ,hadoop-2.6.0-cdh5.7.0.tar.gz
更改 hadoop 配置 (hadoop_home/etc/hadoop) :
启动HDFS:格式化文件系统,进入bin目录,ce,之后启动 hdfs,sbin/start-dfs.sh,使用jps查看 DataNode 以及 NameNode 是否启动成功,或者通过浏览器端口 50070。
停止HDFS:sbin/stop-dfs.sh
HDFS Shell hdfs dfs和hadoop fs指令相同,直接输入后可以看见其他后续指令。
1 2 3 4 5 6 7 8 9 10 11 12 hdfs dfs -ls / hdfs dfs -put test.log / 向HDFS存放文件 hdfs dfs -text /test.log 查看 hdfs dfs -cat /test.log 查看 hdfs dfs -mkdir /tt hdfs dfs -mkdir -p /tt/a/b 递归创建 hdfs dfs -ls /tt/a hdfs dfs -ls /tt/a/b hdfs dfs -ls -R / 递归查看 hdfs dfs -get /test.log 从HDFS中获取文件 hdfs dfs -rm /test.log 删除文件 hdfs dfs -rm -R /tt 删除目录
HDFS Java API 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 public static final String HDFS_PATH = "hdfs://10.211.55.6:8020" ; FileSystem fileSystem = null ; Configuration configuration = null ; @Before public void setUp () throws Exception System.out.println("HDFSApp.setUp" ); configuration = new Configuration(); fileSystem = FileSystem.get(new URI(HDFS_PATH), configuration, "parallels" ); } @After public void tearDown () throws Exception configuration = null ; fileSystem = null ; System.out.println("HDFSApp.tearDown" ); } @Test public void mkdir () throws Exception fileSystem.mkdirs(new Path("/hdfsapi/test2" )); } @Test public void create () throws Exception FSDataOutputStream output = fileSystem.create(new Path("/hdfsapi/test2/a.txt" )); output.write("hello hadoop" .getBytes()); output.flush(); output.close(); } @Test public void cat () throws Exception FSDataInputStream in = fileSystem.open(new Path("/hdfsapi/test2/a.txt" )); IOUtils.copyBytes(in, System.out, 1024 ); in.close(); } @Test public void rename () throws Exception Path oldPath = new Path("/hdfsapi/test/a.txt" ); Path newPath = new Path("/hdfsapi/test/b.txt" ); fileSystem.rename(oldPath, newPath); } @Test public void copyFromLocalFile () throws Exception Path localPath = new Path("/Users/Finch/Downloads/springboot2.1.7.pom" ); Path hdfsPath = new Path("/hdfsapi/test" ); fileSystem.copyFromLocalFile(localPath, hdfsPath); } @Test public void copyFromLocalFileWithProgress () throws Exception InputStream in = new BufferedInputStream( new FileInputStream( new File("/Users/rocky/source/spark-1.6.1/spark-1.6.1-bin-2.6.0-cdh5.5.0.tgz" ))); FSDataOutputStream output = fileSystem.create(new Path("/hdfsapi/test/spark-1.6.1.tgz" ), new Progressable() { public void progress () System.out.print("." ); } }); IOUtils.copyBytes(in, output, 4096 ); } @Test public void copyToLocalFile () throws Exception Path localPath = new Path("/Users/rocky/tmp/h.txt" ); Path hdfsPath = new Path("/hdfsapi/test/hello.txt" ); fileSystem.copyToLocalFile(hdfsPath, localPath); } @Test public void listFiles () throws Exception FileStatus[] fileStatuses = fileSystem.listStatus(new Path("/hdfsapi/test" )); for (FileStatus fileStatus : fileStatuses) { String isDir = fileStatus.isDirectory() ? "文件夹" : "文件" ; short replication = fileStatus.getReplication(); long len = fileStatus.getLen(); String path = fileStatus.getPath().toString(); System.out.println(isDir + "\t" + replication + "\t" + len + "\t" + path); } } @Test public void delete () throws Exception fileSystem.delete(new Path("/" ), true ); }
HDFS读写原理 通过漫画轻松掌握HDFS工作原理
HDFS优缺点 优点:数据冗余、硬件容错;可构建在廉价机器上;适合存储大文件。
缺点:数据访问延迟(想要极快进行数据检索并不现实);不适合小文件存储(小文件太多会导致NameNode占用内存信息越多,增加了NameNode压力)。
YARN 资源调度框架YARN在1.x时代只支持MapReduce任务,而在2.x之后可以让更多的计算框架(如Spark、Storm)运行在集群里面,不同的计算框架可以共享同一个HDFS的数据,享受整体的资源调度。
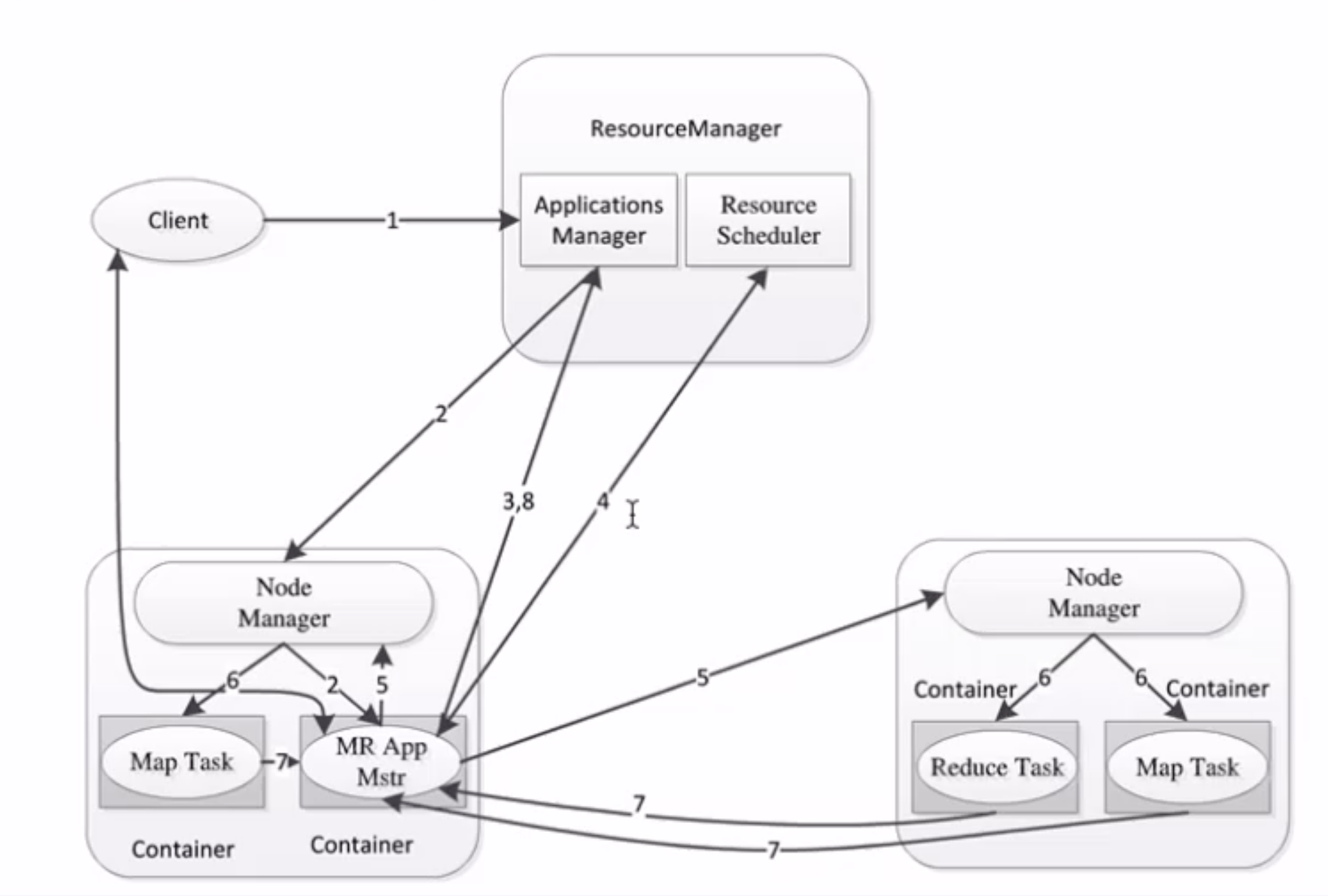
YARN架构 ResourceManager: RM
整个集群同一时间提供服务的RM只有一个(可以使用主从解决单点问题),负责集群资源的统一管理和调度
处理客户端的请求: 提交一个作业、杀死一个作业
监控我们的NM,一旦某个NM挂了,那么该NM上运行的任务需要告诉我们的AM来如何进行处理
NodeManager: NM
整个集群中有多个,负责自己本身节点资源管理和使用
定时向RM汇报本节点的资源使用情况
接收并处理来自RM的各种命令:启动Container
处理来自AM的命令
单个节点的资源管理
ApplicationMaster: AM
每个应用程序对应一个:MR、Spark,负责应用程序的管理
为应用程序向RM申请资源(core、memory),分配给内部task
需要与NM通信:启动/停止task,task是运行在container里面,AM也是运行在container里面
Container
封装了CPU、Memory等资源的一个容器
是一个任务运行环境的抽象
Client
运行流程 https://github.com/heibaiying/BigData-Notes/blob/master/notes/Hadoop-YARN.md
Client 提交作业到 YARN 上;Resource Manager 选择一个 Node Manager,启动一个 Container 并运行 Application Master 实例;Application Master 根据实际需要向 Resource Manager 请求更多的 Container 资源(如果作业很小, 应用管理器会选择在其自己的 JVM 中运行任务);Application Master 通过获取到的 Container 资源执行分布式计算。
YARN伪分布式环境搭建 1)mapred-site.xml [ mapred-site.xml.template 改名去后缀 ]
1 2 3 4 <property > <name > mapreduce.framework.name</name > <value > yarn</value > </property >
2)yarn-site.xml
1 2 3 4 <property > <name > yarn.nodemanager.aux-services</name > <value > mapreduce_shuffle</value > </property >
3) 启动YARN相关的进程
4)验证
jps:ResourceManager 、NodeManager
访问8088端口
5)停止YARN相关的进程
提交mr作业到YARN上运行:
MapReduce 优点:海量数据离线处理
缺点:实时流式计算
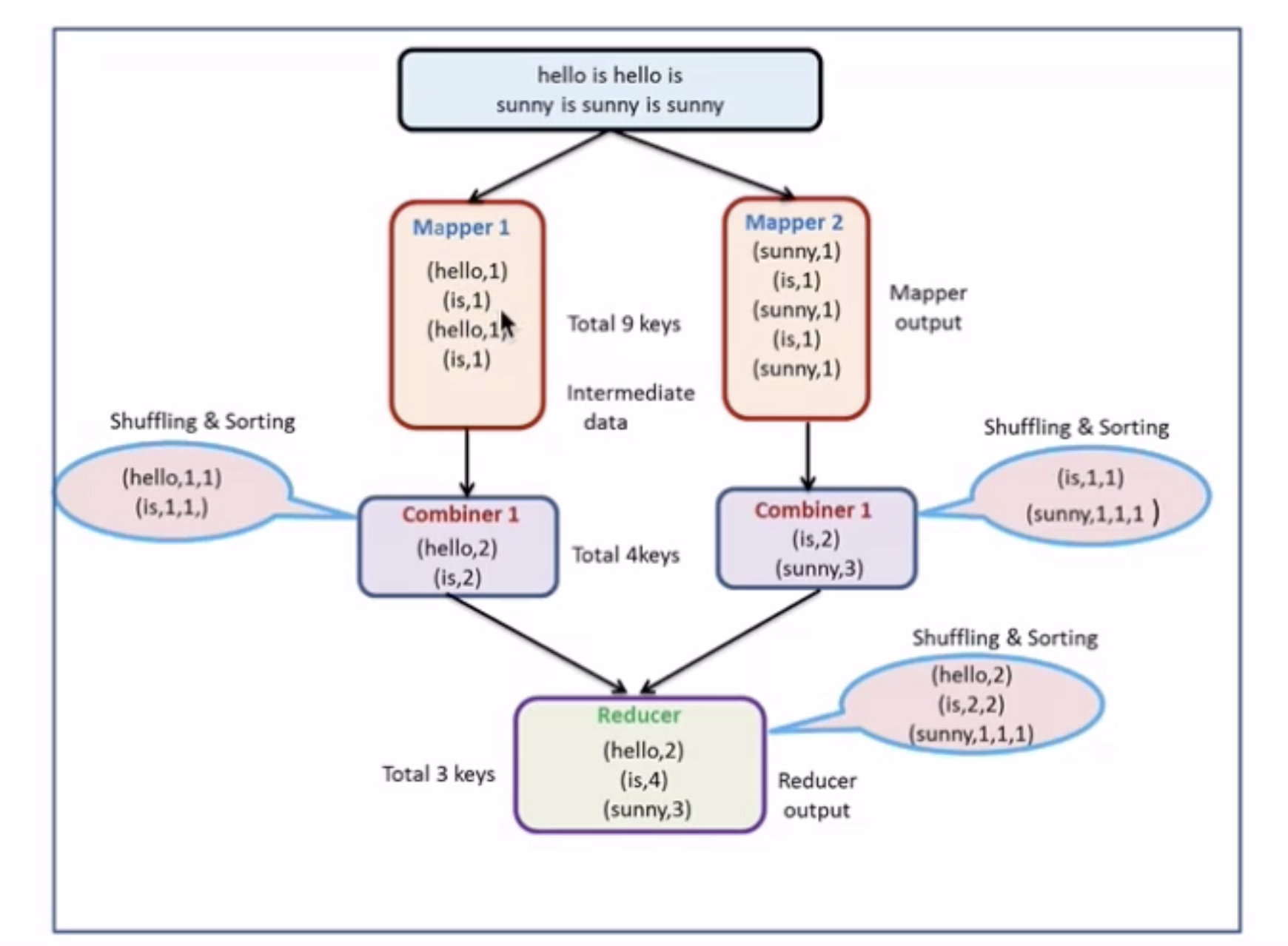
入门案例:wordcount: 统计文件中每个单词出现的次数,借用 MapReduce 可以实现分而治之。
MapReduce 框架专门用于键值对处理,它将作业的输入视为一组对,并生成一组对作为输出。输出和输出的 key 和 value 都必须实现Writable 接口。 key classes 还必须实现 WritableComparable 接口。
1 (input) <k1, v1> -> map -> <k2, v2> -> combine -> <k2, v2> -> reduce -> <k3, v3> (output)
核心概念 Split: 交由MapReduce作业来处理的数据块,是MapReduce中最小的计算单元。HDFS中 blocksize 是HDFS中最小的存储单元 128M。默认情况下:他们两是一一对应的,当然我们也可以手工设置他们之间的关系(不建议)
InputFormat: 将我们的输入数据进行分片(split): InputSplit[] getSplits(JobConf job, int numSplits) throws IOException;TextInputFormat: 处理文本格式的数据
OutputFormat: 输出
Combiner
Partitioner
MapReduce 2.x 架构 Java 版 WordCount 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class WordCountApp public static class MyMapper extends Mapper <LongWritable , Text , Text , LongWritable > LongWritable one = new LongWritable(1 ); protected void map (LongWritable key, Text value, Context context) throws IOException, InterruptedException String line = value.toString(); String[] words = line.split(" " ); for (String word : words) { context.write(new Text((word)), one); } } } public static class MyReducer extends Reducer <Text , LongWritable , Text , LongWritable > protected void reduce (Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException long sum = 0 ; for (LongWritable value : values) { sum += value.get(); } context.write(key, new LongWritable(sum)); } } public static void main (String[] args) throws IOException, ClassNotFoundException, InterruptedException Configuration configuration = new Configuration(); Path outputPath = new Path(args[1 ]); FileSystem fileSystem = FileSystem.get(configuration); if (fileSystem.exists(outputPath)) { fileSystem.delete(outputPath,true ); System.out.println("output file exists, but is has deleted" ); } Job job = Job.getInstance(configuration, "wordcount" ); job.setJarByClass(WordCountApp.class ) ; FileInputFormat.setInputPaths(job, new Path(args[0 ])); job.setMapperClass(MyMapper.class ) ; job.setMapOutputKeyClass(Text.class ) ; job.setMapOutputValueClass(LongWritable.class ) ; job.setReducerClass(MyReducer.class ) ; job.setOutputKeyClass(Text.class ) ; job.setOutputValueClass(LongWritable.class ) ; job.setCombinerClass(MyReducer.class ) ; FileOutputFormat.setOutputPath(job, new Path(args[1 ])); System.exit(job.waitForCompletion(true ) ? 0 : 1 ); } }
执行:
1 hadoop jar /home/hadoop/lib/hadoop-train-1.0.jar com.hadoop.mapreduce.WordCountApp hdfs://10.211.55.6:8020/hello.txt hdfs://10.211.55.6:8020/output/wc
Combiner
本地的Reduce;
减少Map Tasks输出的数据量及数据网络传输量;
但适用场景有限,比如求和计数等,不适合求平均数等类似场景。
Partitioner Partitioner决定Map Task输出的数据交由哪个Reduce Task处理。默认实现:分发的key的hash值对Reduce Task个数取模。
案例:手机销量手机按品牌分类收集至各个文件中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 public static class MyMapper extends Mapper <LongWritable , Text , Text , LongWritable > protected void map (LongWritable key, Text value, Context context) throws IOException, InterruptedException String line = value.toString(); String[] words = line.split(" " ); context.write(new Text((words[0 ])), new LongWritable(Long.parseLong(words[1 ]))); } } public static class MyPartitioner extends Partitioner <Text , LongWritable > public int getPartition (Text key, LongWritable value, int numPartitions) if (key.toString().equals("xiaomi" )){ return 0 ; } if (key.toString().equals("huawei" )){ return 1 ; } if (key.toString().equals("iphone7" )) { return 2 ; } return 3 ; } } public static void main (String[] args) throws IOException, ClassNotFoundException, InterruptedException ... job.setPartitionerClass(MyPartitioner.class ) ; job.setNumReduceTasks(4 ); FileOutputFormat.setOutputPath(job, new Path(args[1 ])); System.exit(job.waitForCompletion(true ) ? 0 : 1 ); }
JobHistory JobHistory是一个Hadoop自带的历史服务器,它用于记录已运行完的MapReduce信息到指定的HDFS目录下。可以通过HTTP页面访问获得信息。
mapred-site.xml 添加:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 <property > <name > mapreduce.jobhistory.address</name > <value > 192.168.77.130:10020</value > <description > MapReduce JobHistory Server IPC host:port</description > </property > <property > <name > mapreduce.jobhistory.webapp.address</name > <value > 192.168.77.130:19888</value > <description > MapReduce JobHistory Server IPC host:port</description > </property > <property > <name > mapreduce.jobhistory.done-dir</name > <value > /history/done</value > </property > <property > <name > mapreduce.jobhistory.intermediate-done-dir</name > <value > /history/done_intermediate</value > </property >
yarn-site.xml 添加:
1 2 3 4 5 <property > <name > yarn.log-aggregation-enable</name > <value > true</value > </property >
之后需要重启YARN访问,stop-yarn.sh 以及 start-yarn.sh。
启动 sbin/mr-jobhistory-daemon.sh start historyserver,在19888端口处就可以看到接下来的执行信息了。
https://blog.51cto.com/zero01/2093445