
网络基础
网络模型
国际标准化组织制定的 OSI 网络模型:
应用层,负责为应用程序提供统一的接口。
表示层,负责把数据转换成兼容接收系统的格式。
会话层,负责维护计算机之间的通信连接。
传输层,负责为数据加上传输表头,形成数据包。
网络层,负责数据的路由和转发。
数据链路层,负责 MAC 寻址、错误侦测和改错。
物理层,负责在物理网络中传输数据帧。
OSI 模型过于复杂,没有提供一个可实现的方法。所以在 Linux 中实际上使用的是四层模型,即 TCP/IP 网络模型:
应用层,负责向用户提供一组应用程序,比如 HTTP、FTP、DNS 等。
传输层,负责端到端的通信,比如 TCP、UDP 等。
网络层,负责网络包的封装、寻址和路由,比如 IP、ICMP 等。
网络接口层,负责网络包在物理网络中的传输,比如 MAC 寻址、错误侦测以及通过网卡传输网络帧等。
Linux 网络栈及收发流程
TCP/IP 模型后,在进行网络传输时,数据包就会按照协议栈,对上一层发来的数据进行逐层处理;然后封装上该层的协议头,再发送给下一层:
传输层在应用程序数据前面增加了 TCP 头;
网络层在 TCP 数据包前增加了 IP 头;
网络接口层,又在 IP 数据包前后分别增加了帧头和帧尾。
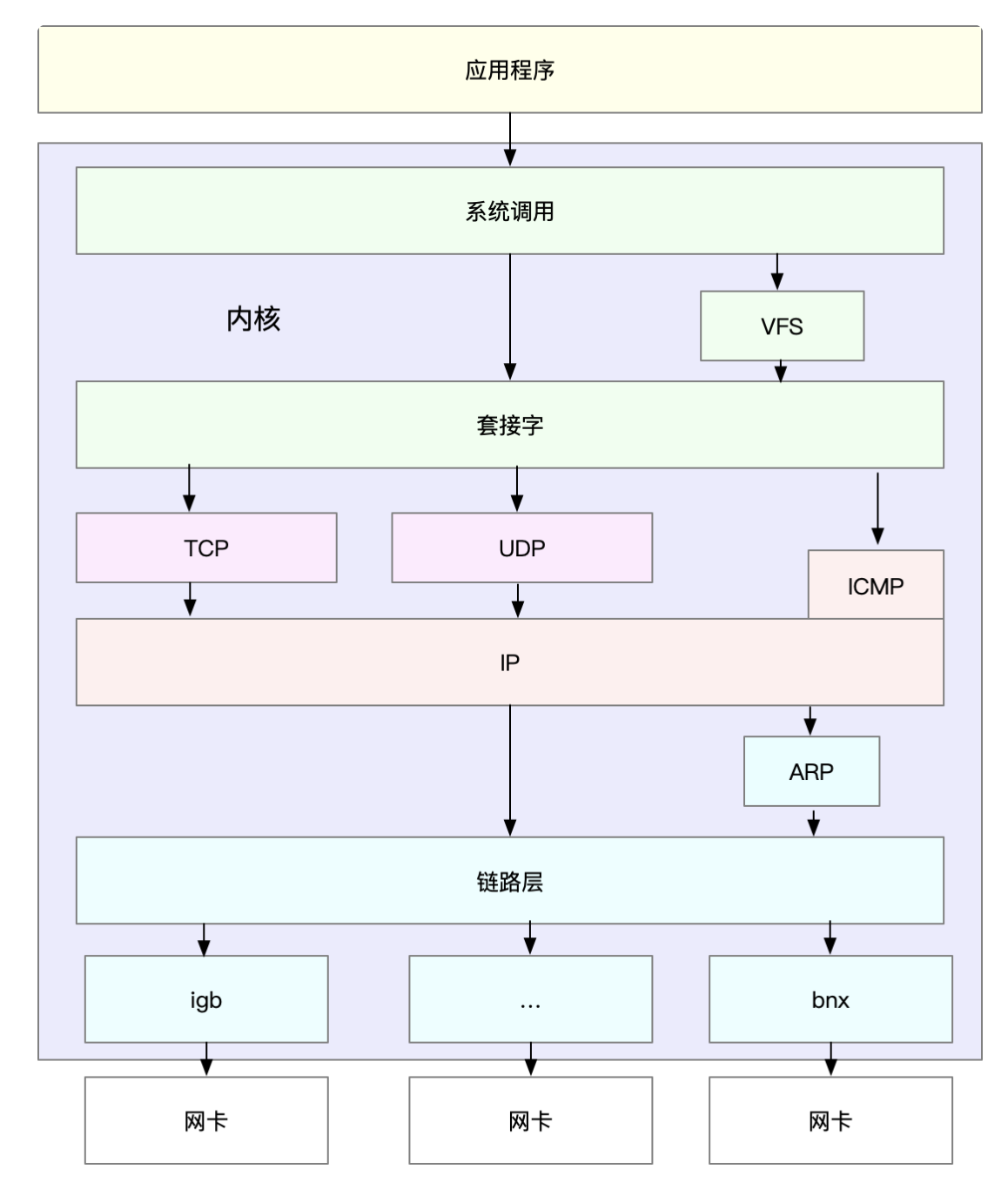
Linux 内核中的网络栈,其实也类似于 TCP/IP 的四层结构。
最上层的应用程序,需要通过系统调用,来跟套接字接口进行交互;
套接字的下面,就是我们前面提到的传输层、网络层和网络接口层;
最底层,则是网卡驱动程序以及物理网卡设备。
接收
当一个网络帧到达网卡后,网卡会通过 DMA 方式,把这个网络包放到收包队列中;然后通过硬中断,告诉中断处理程序已经收到了网络包。
接着,网卡中断处理程序会为网络帧分配内核数据结构(sk_buff),并将其拷贝到 sk_buff 缓冲区中;然后再通过软中断,通知内核收到了新的网络帧。
内核协议栈从缓冲区中取出网络帧,并通过网络协议栈,从下到上逐层处理这个网络帧:
- 在链路层检查报文的合法性,找出上层协议的类型(比如 IPv4 还是 IPv6),再去掉帧头、帧尾,然后交给网络层。
- 网络层取出 IP 头,判断网络包下一步的走向,比如是交给上层处理还是转发。当网络层确认这个包是要发送到本机后,就会取出上层协议的类型(比如 TCP 还是 UDP),去掉 IP 头,再交给传输层处理。
- 传输层取出 TCP 头或者 UDP 头后,根据 < 源 IP、源端口、目的 IP、目的端口 > 四元组作为标识,找出对应的 Socket,并把数据拷贝到 Socket 的接收缓存中。
- 应用程序就可以使用 Socket 接口,读取到新接收到的数据了。
发送
应用程序调用 Socket API(比如 sendmsg)发送网络包。这是一个系统调用,所以会陷入到内核态的套接字层中。套接字层会把数据包放到 Socket 发送缓冲区中。
网络协议栈从 Socket 发送缓冲区中,取出数据包;再按照 TCP/IP 栈,从上到下逐层处理。比如,传输层和网络层,分别为其增加 TCP 头和 IP 头,执行路由查找确认下一跳的 IP,并按照 MTU 大小进行分片。
分片后的网络包,再送到网络接口层,进行物理地址寻址,以找到下一跳的 MAC 地址。然后添加帧头和帧尾,放到发包队列中。这一切完成后,会有软中断通知驱动程序:发包队列中有新的网络帧需要发送。
最后,驱动程序通过 DMA ,从发包队列中读出网络帧,并通过物理网卡把它发送出去。
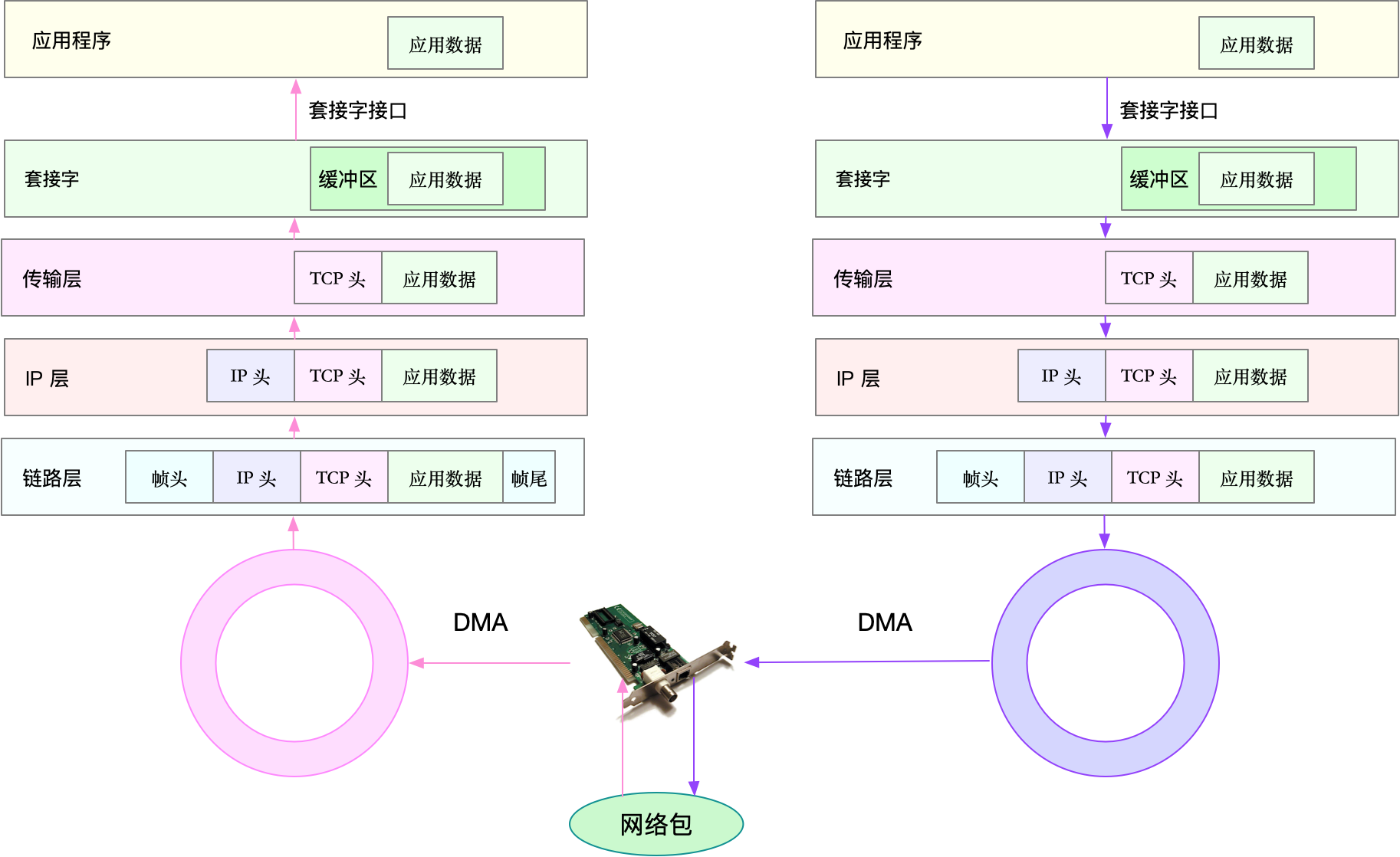
总结而言:应用程序通过套接字接口发送数据包时,先要在网络协议栈中从上到下逐层处理,然后才最终送到网卡发送出去;而接收数据包时,也要先经过网络栈从下到上的逐层处理,最后送到应用程序。
网络性能指标
带宽:链路的最大传输速率,单位通常为 b/s (比特 / 秒)。
吞吐量:单位时间内成功传输的数据量,单位通常为 b/s(比特 / 秒)或者 B/s(字节 / 秒)。吞吐量受带宽限制,而吞吐量 / 带宽,也就是该网络的使用率。
延时,表示从网络请求发出后,一直到收到远端响应,所需要的时间延迟。在不同场景中,这一指标可能会有不同含义。比如,它可以表示,建立连接需要的时间(比如 TCP 握手延时),或一个数据包往返所需的时间(比如 RTT)。
PPS,是 Packet Per Second(包 / 秒)的缩写,表示以网络包为单位的传输速率。PPS 通常用来评估网络的转发能力,比如硬件交换机,通常可以达到线性转发(即 PPS 可以达到或者接近理论最大值)。而基于 Linux 服务器的转发,则容易受网络包大小的影响。
查看网络接口配置
ifconfig eth0 或 ip -s addr show dev eno1,其中的 -s 即 statistics,表示详细统计信息。
1 | 2: eno1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 |
第一,网络接口的状态标志。 ip 输出中的 LOWER_UP ,都表示物理网络是连通的
第二,MTU 的大小。MTU 默认大小是 1500,根据网络架构的不同,可能需要调大或者调小 MTU 的数值。
第三,网络接口的 IP 地址、子网以及 MAC 地址。
第四,网络收发的字节数、包数、错误数以及丢包情况,特别是 TX (发送)和 RX(接收) 部分的 errors、dropped、overruns、carrier 以及 collisions 等指标不为 0 时,通常表示出现了网络 I/O 问题。其中:errors 表示发生错误的数据包数,比如校验错误、帧同步错误等;dropped 表示丢弃的数据包数,即数据包已经收到了 Ring Buffer,但因为内存不足等原因丢包;overruns 表示超限数据包数,即网络 I/O 速度过快,导致 Ring Buffer 中的数据包来不及处理(队列满)而导致的丢包;carrier 表示发生 carrirer 错误的数据包数,比如双工模式不匹配、物理电缆出现问题等;collisions 表示碰撞数据包数。
查看套接字
1 | # -l 表示只显示监听套接字 |
查看网络吞吐量和PPS
sar 增加 -n 参数就可以查看网络的统计信息,比如网络接口(DEV)、网络接口错误(EDEV)、TCP、UDP、ICMP 等等。
1 |
|
rxpck/s 和 txpck/s 分别是接收和发送的 PPS,单位为包 / 秒。
rxkB/s 和 txkB/s 分别是接收和发送的吞吐量,单位是 KB/ 秒。
rxcmp/s 和 txcmp/s 分别是接收和发送的压缩数据包数,单位是包 / 秒。
查看带宽则是使用ethtool。
1 | ethtool eth0 | grep Speed |
连通性
使用基于ICMP的ping
1 | # -c3表示发送三次ICMP包后停止 |
补充:
使用 iperf 检查宿主机之间的带宽
以 iperf2 为例,查找文档时不要混淆了 iperf2 和 iperf3。需要在服务端和客户端各起一个测试进程:
- 服务端:iperf -s -p 9999
- 客户端:iperf -c $SERVER_IP -p 9999 -i 1
注意:服务端标准输出显示的是服务端的入站带宽(download / ingress),客户端标准输出显示的是客户端的出站带宽(upload / egress),在使用工具(如 tc)修改网络设置后,明白这点很重要。
使用 qperf 检查宿主机之间的延迟
同样需要在服务端和客户端各起一个测试进程:
- 服务端:qperf
- 客户端:qperf -vvs $SERVER_IP tcp_lat
qperf 也可用于检查带宽,但是依然建议使用 iperf 检查,iperf 这个工具更加成熟。
Ref: How to use qperf to measure network bandwidth and latency performance?